分块查找(Blocking Search)又称作索引顺序查找,是一种在数据量较大的情况下,进行改进的一种查找方式,同排序算法的外排方式类似。分块查找是一种介于顺序查找和二分查找的算法。它主要由两部分组成:索引和有序的块(块中可无序)。
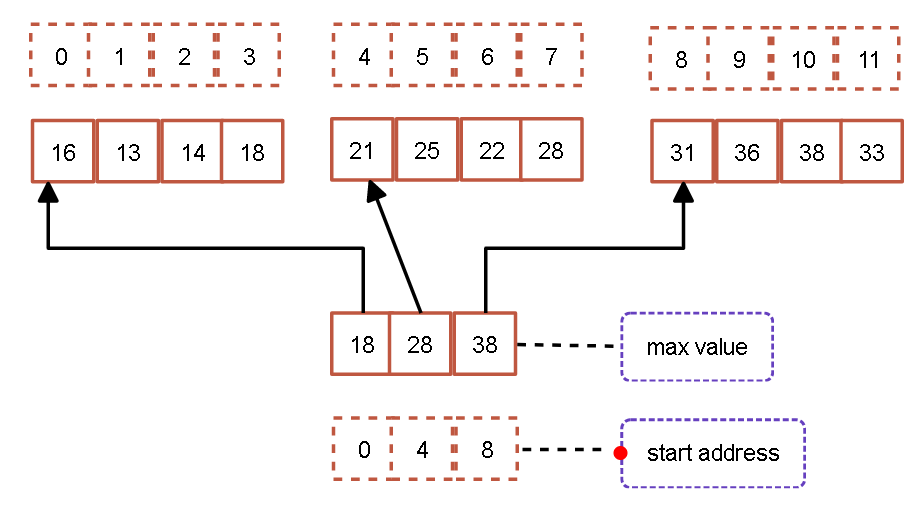
根据上图,数据{18,28,38} 属于索引部分,整个数据部分由三个大块{16,13,14,18}、{21,25,22,28},{31,36,38,33} 组成。索引部分是由从三个数据部分中获取的最大值组成,不仅如此,索引中还记录了最大值与最大值所在块的起始位置。
例如,当需要查找数据25时,首先对索引表进行查找(可以是顺序查找),由于第一个块中最大值为18,因此25不一定在第一个块中,第二个块的最大值是28,因此25有可能在第二个块中,28对应块的起始位置是4,结束位置为第三个块的起始位置减一,因此查找区间为[4,7],对该区间进行顺序查找,确定25是否在该数值序列中。
在数据量较大时,分块查找也能应对。例如,有10000MB的数据,而当前系统可用内存是100MB,一种简单的方法是每次从数据中读取100MB到系统内存中,然后依次进行比较。此种方法相对耗时交材,而采用分块查找则可以只需要构建1~10MB的索引即可,每个块保持有序,每个文件内的数据也不必有序,分块查找则首先通过访问内存中的索引数据,确定数据对应的文件块,然后在对该文件块内的数据进行查找,以减少数据的查找次数。
分块查找的算法效率介于顺序查找和二分查找之间。在实际应用中,分块后的数据块大小不一定是平均的,可以根据实际情况按照数值的特征进行分块。分块查找不仅仅可以高效地进行查找,而且当向数据中插入和删除某条记录时,也只需定位到所属的数据块,然后对相应的数据块进行操作即可,而数据块内的数据本身是无序的,所以插入数据或者删除数据都不必移动大量的数据。它的主要缺陷在于需要一个辅助索引结构存储块的最大值和块的起始位置,以及初始化块需要的排序开销。